
漏洞利用——从shellcode 到安全防护
漏洞利用
基本概念
- Exploit(漏洞利用)——指利用已有漏洞进行尝试/发起实质攻击。
其核心就在于利用程序漏洞去劫持进程的控制权,实现控制流劫持,以便执行植入的shellcode或者达到其它目的。早期攻击通常采用代码植入(上载一段代码,控制进程转向这段代码去执行,即劫持了进程的控制权)的方式,但是我们通常把它作为一个攻击动作的统称,实际动作还是看结构里的东西。
有漏洞不一定就有Exploit,因为其相较于vulnerable需要具备可行性
Shellcode 在广义上表示为植入进程的代码
Exploit结构:
payload(触发漏洞,转移控制权) Shellcode 负责包含shellcode,并加壳(以触发漏洞并让系统/程序执行shellcode) 用来实现具体功能 Shellcode植入
以一个含验证过程漏洞的程序案例展开,
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
int verify(char* code)
{
int flag;
char buffer[44]; //考虑去覆盖
flag = strcmp(REGCODE, code); //做比较,去覆盖的code要小于REGCODE,此时比较后flag=1
//将code填入buffer,因为44位占满后会在末尾补00,因为会将flag的01占用掉,改成00;
strcpy(buffer, code);
return flag; //此时flag返回的结果就是0了
}
int main()
{
int vFlag = 0;
char regcode[256];
memset(regcode, 0, 256);
FILE* fp;
LoadLibraryA("user32.dll"); //在windows.h中定义,用于加载MessageBoxA函数
if (!(fp = fopen("reg.txt", "rb")))
{
exit(0);
}
fread(regcode, 256, 1, fp);
vFlag = verify(regcode);
if (vFlag)
{
printf("wrong regcode!"); //为1时打印
}
else
{
printf("passed!"); //为0时打印
}
fclose(fp);
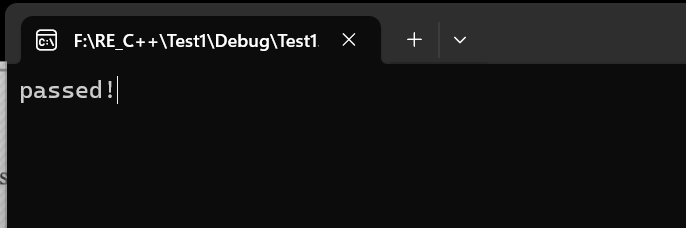
} (覆盖返回地址法)因为代码会自动在txt文本后填入00,因此我们在txt文本中构造一个44字节的输入(前8位小于密码),以此达到溢出效果;因此当我们对代码完成编译后,利用x32dbg即可在单步运行中查看到对应的结果显示在随机构造44个数字输入后,程序仍成功运行。

基于此,我们尝试用shellcode植入通过buffer(44)去盖住自己,flag(4)和EBP(4)返回地址,使得程序调出消息框的部分换掉53-56字节代码的入口,观察MessagbboxA的函数结构如下:
1 | int MessageBoxA( |
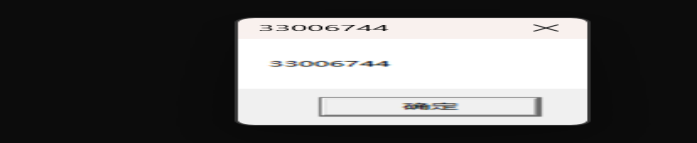
因此我们在x32dbg中调出此API的汇编代码,转换为机器码用16进制工具Hxd填入刚才的reg.txt文件中(在调用前需要将函数的四个参数输入进去,注意顺序要相反,图中内容仅示例),按序提取机器代码,改写为shellcode

我们整理这段机器代码,可以替换两个字符串中得内容,比如随机输入4个数字,同时利用vs studio在verify函数入口打断点,进入调试模式,查看buffer地址,之后利用HdX将机器代码编写进,53-56字节存放buffer地址用于覆盖返回地址,之间用无含义编码NOF(也就是0X90)Reg.txt文本,完成shellcode编写,之后运行.exe文件发现可弹出我们设计好的Shell;至此我们便学会了基于地址覆盖的Shellcode编写.
Shellcode编写
编写的难点
- 特定字符需要转码(shellcode中若有00还需要转码)
- 函数的API需要动态获取(远程操作难定位)
- 对于特定操作需要转码(例如我们无法直接push 0 ,那就异或EBX,再传入)
编写方法
我们先编写一个最简单的窗口调出代码
1 |
|
编译后可在vs studio中通过反汇编查看对应汇编代码,若出现push 0 需要通过xor ebx ebx得到0,再push ebx达到同等效果,因此我们可以将其写为汇编形式
1 |
|
此时再次反汇编查看即可在内存中得到shellcode的机器代码,将其用HxD写入Reg.txt即可构造完整的shellcode。
编写必要性
我们选择编码对exploit变形的原因主要在于应用程序/应用平台的不同,会使字符集有差异从而限制exploit的稳定性;同时对于“危险字符”的变形或者截断会破坏exploit,比如strpy函数对于NULL字符就不可接纳,还会限制0x0D或0x20等字符,因此也需要编写来绕过;同时通过编写以绕过安全检测工具的检测特征也可实现一定程度上的免杀。
网页Shellcode
常用base64进行编码。base64是网络上最常见,用于传输8bit字节码的编码方式之一,基于64个可打印字符来表示二进制数据。对于二进制机器代码的编码采用类似于“加壳”的思想:自定义编码(异或,计算,加解密等)→构造解码程序置于shellcode开始执行的地方;当exploit成功,shellcode顶部的解码程序会首先运行将内存中的代码还原成真正的shellcode,然后执行。
异或编码
一种简易的编码方法,但在选取编码字节时不可与已有字节相同,否则会出现0(就是怕异或出终止字符00)。用于编码的程序说独立的,在生成shellcode的编码阶段使用;将shellcode代码输入后在结尾放置空指令“\x90”,从而输出异或后的编码。(用一段代码来做示例)
1 |
|
输出结果即为编码后shellcode;
Shellcode解码
因为完整的shellcode=解码程序(释放的)+编码的shellcode(套壳的)。解码程序(依旧是用之前的key去进行异或得到解码的shellcode)可正常运行的前提为eax在完整的shellcode运行前指向完整的shellcode起始位置,解码程序也要用汇编写。
1 | void main() |
得到相应的机器代码\x83\xc0\x14\x33\xc9\x8a\x1c\x08\x80\xf3\x44\x88\x1c\x08\x41\x80\xfb\x90\x75\xf1
完整的shellcode
在c语言中写入时,代码前需无回车且不能注释且每个字节前加“\x”;
1 |
|